
How Code Works
Memory Randomization
Memory layouts have evolved a lot over time, but there are still fundamental problems that have plagued them all. The image below shows the progress that has been made.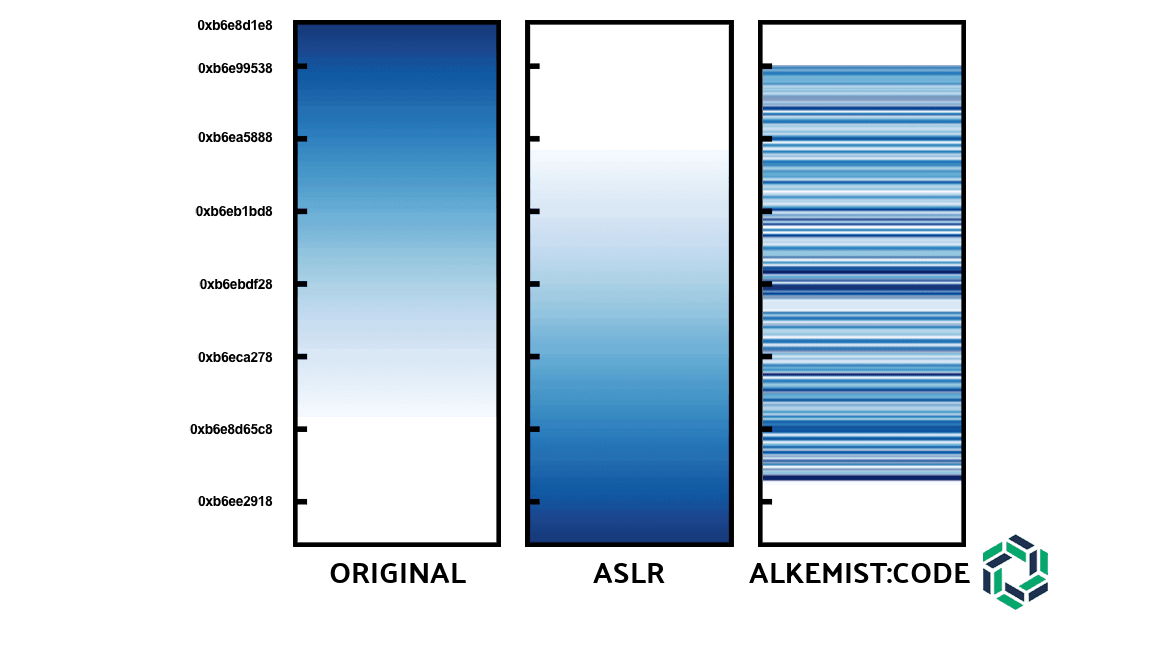 The layout on the left is representative of a program built in the late 90s. Each time a program was executed, or library loaded, the memory addresses of each program were the same.The center layout shows Address Space Layout Randomization (ASLR). In the early 2000s most OSes began adopting ASLR to help prevent attackers from always knowing where their targets would exist. ASLR randomizes the base address of a program each time it is executed, but has an inherent weakness in that the whole program is moved as one unit. Introduction of ASLR made exploitation of memory corruption vulnerabilities more difficult, but ASLR can be defeated easily by one information leak or enough time spent analyzing a target binary.As shown in the right layout, Code improves upon the ASLR concept by randomizing each function within a program. An attacker can no longer know the distances between functions in memory, neutralizing memory-based attacks, which are used in 75% of cyber kill chains and comprise 70% of all bugs in both Google Chrome and Windows.
The layout on the left is representative of a program built in the late 90s. Each time a program was executed, or library loaded, the memory addresses of each program were the same.The center layout shows Address Space Layout Randomization (ASLR). In the early 2000s most OSes began adopting ASLR to help prevent attackers from always knowing where their targets would exist. ASLR randomizes the base address of a program each time it is executed, but has an inherent weakness in that the whole program is moved as one unit. Introduction of ASLR made exploitation of memory corruption vulnerabilities more difficult, but ASLR can be defeated easily by one information leak or enough time spent analyzing a target binary.As shown in the right layout, Code improves upon the ASLR concept by randomizing each function within a program. An attacker can no longer know the distances between functions in memory, neutralizing memory-based attacks, which are used in 75% of cyber kill chains and comprise 70% of all bugs in both Google Chrome and Windows.Functionally Identical, Logically Unique
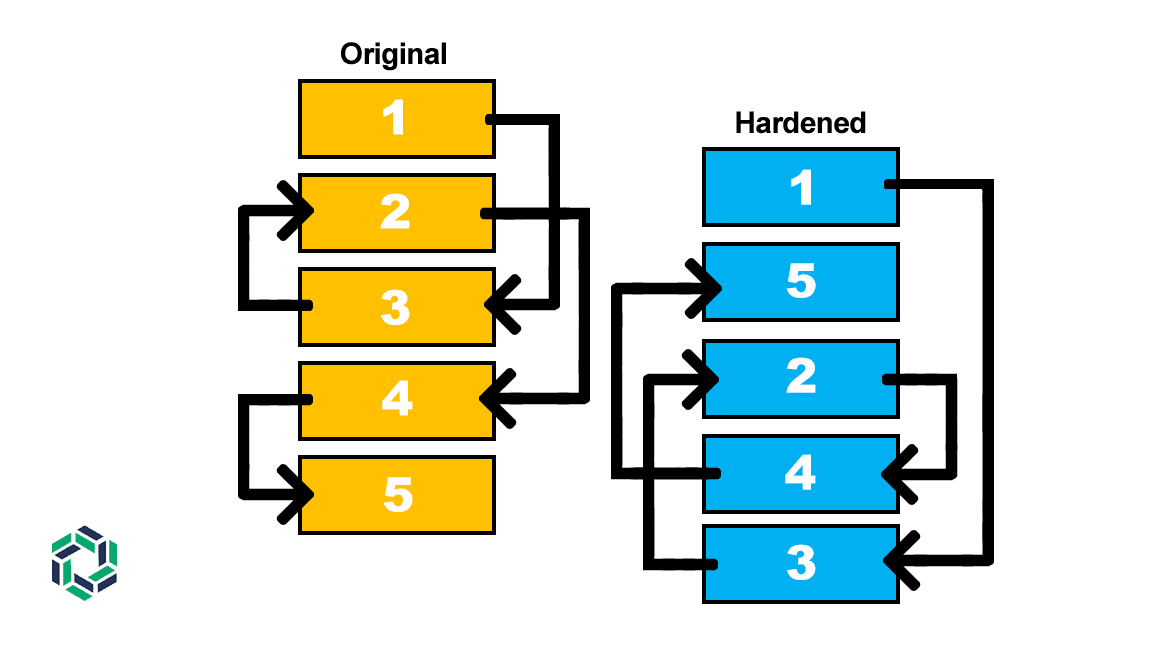
An important aspect of Code is that while functions move around in memory, the functionality of the program stays identical. One way to assess functionality is to look at the call graph of a program. Let’s consider a simple program with five functions with a call graph shown on the left side of the figure below. The call graph would read: Function 1 calls Function 3, Function 3 calls Function 2, Function 2 calls Function 4, and Function 4 calls Function 5. For simplicity’s sake, consider all functions to be contiguous in memory in the order shown in the figure. On the right is the same program, with the same five functions, after the program begins executing and Code randomizes the functions in memory. You will see that while the functions are not in the same location, the call graph is the same.
Disrupt Hacker Economics
By building Code into your software, you deprive the attacker the ability to reliably exploit your software because the code they need to execute is never in the same place twice. Additionally, any failed attempts to exploit Code-protected software result in the program crashing. When the software is launched again, any information an attacker could gain from the previous failed exploit attempt would not be useful because the program will have been randomized again.Integrate with Existing Tooling
Code allows you to continue using your existing compiler and linker. We accomplish this by sitting in front of the linker, making the modifications needed, and then calling your linker. This process can be seen in the figure below. The top path through the process is what a normal build looks like, abstracting away the infinite complexities that build systems bring. Code has been proven to work with builds as simple as a “Hello, World” example built with GCC all the way to a complex Yocto-based build using different compilers per project. With Code in the mix, compilation takes a slightly different path at the linking stage, where we inject information needed to accomplish our runtime randomization.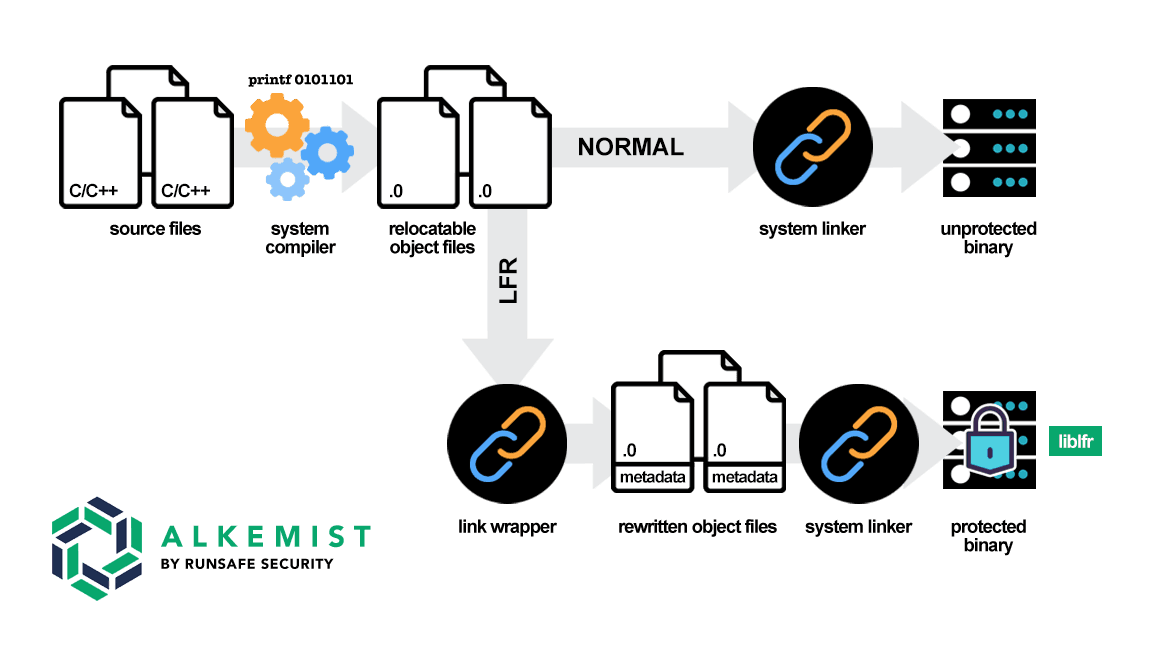 Repo applies all of this technology in pre-built packages of open-source applications to allow you to gain the protections of Code by simply changing where you pull your deployment's apks, debs, rpms, or Docker images from.
Repo applies all of this technology in pre-built packages of open-source applications to allow you to gain the protections of Code by simply changing where you pull your deployment's apks, debs, rpms, or Docker images from.